在 搬瓦工 的所有机房中,中国香港 HKHK_8 机房无疑是定位最高、价格最昂贵的存在。
不仅能够提供媲美中国大陆本土服务器的访问体验,同时又完全免去了繁琐的 ICP 备案流程。对于追求极致稳定性的业务部署、高权重独立站或企业级应用而言,HKHK_8 几乎是免备案 VPS 的天花板。
但这台机器的真实网络表现,是否真的能够支撑起它高昂的售价?
接下来,本文将抛开主观评价,直接通过底层的硬件 I/O 测试、三网回程路由追踪(BestTrace)以及全国 Ping 值监控,用客观数据对 HKHK_8 进行一次完整的实测还原。
HKHK_8 全国延迟与丢包率实测
评价香港机房质量,最核心的硬性指标就是晚高峰的网络连通率。我们在晚上 9 点至 11 点的跨境网络拥堵高峰期,对搬瓦工香港 HKHK_8 机房进行了多节点的连续探测。
首先看全国多节点的基础 Ping 值表现。
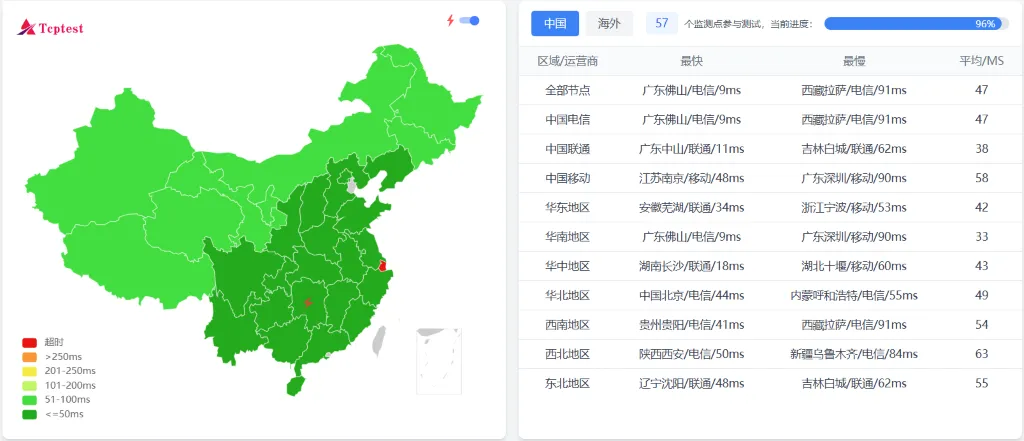
从实测数据来看,搬瓦工香港机房的全国平均延迟稳定在 47ms 左右。为了让大家对这个数字有更直观的体感,我们可以直接对比中国大陆本土的服务器。
以我手里的一台中国成都服务器为例,其全国平均延迟通常在 33ms 左右。而 HKHK_8 作为一个免备案的境外机房,仅仅只有 14ms 的差距,这种微小的延迟差在物理体感上可以说完全没有区别。
对于高客单价的建站业务而言,低延迟固然重要,但更致命的其实是网络丢包。一旦跨境骨干网在晚高峰出现间歇性丢包,就会直接导致网站前端加载卡顿、静态资源加载失败。
以下是我们在晚高峰时段,针对该机房进行的持续高频发包测试。
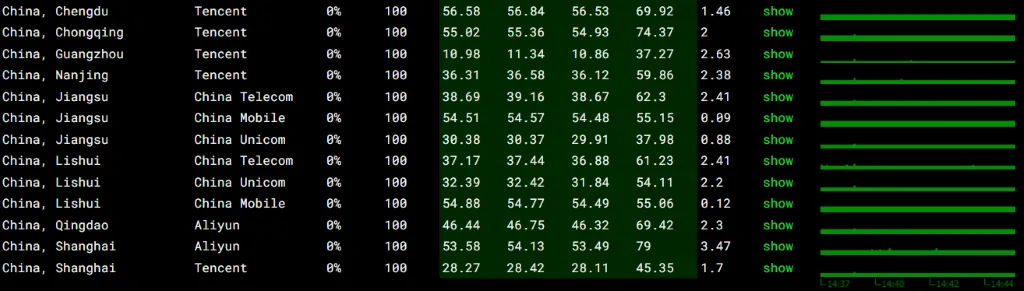
测试结果显示,在骨干网最拥堵的时段,HKHK_8 机房的丢包率依然死死钉在 0%。
对于一条跨境线路来说,晚高峰零丢包意味着极高的业务稳定性。无论是电信、联通还是移动用户访问,都能获得如同访问国内双线机房一样的流畅体验。
这也是该机房能够完美替代国内备案服务器、直接承载高价值商业业务的底层底气。
搬瓦工香港三网回程 CN2 GIA 路由追踪
看完表层的延迟数据,我们需要下探到底层路由。
决定一条香港线路晚高峰是否稳定的核心,在于它回大陆时跨越骨干网的路径选择。测试结论非常明确:电信、联通、移动三网回程,全部强制交汇至电信 CN2 GIA(AS4809)骨干网。
以下是回程路由一键测试脚本的汇总结果:
#############################################################
# BestTrace.sh - Linux VPS 回程路由一键测试 #
#############################################################
节点名称 IP 地址 线路类型
-------------------------------------------------------------
北京电信 219.141.147.210 CN2 GIA
上海电信 202.96.209.133 CN2 GIA
广州电信 202.96.128.86 CN2 GIA
成都电信 118.112.11.12 CN2 GIA
北京联通 202.106.50.1 CN2 GIA
上海联通 210.22.97.1 CN2 GIA
广州联通 210.21.196.6 CN2 GIA
成都联通 119.6.6.6 CN2 GIA
北京移动 221.179.155.161 CN2 GIA
上海移动 211.136.112.200 CN2 GIA
广州移动 120.196.165.24 CN2 GIA
成都移动 211.137.96.205 CN2 GIA
成都教育网 202.112.14.151 CN2 GIA
-------------------------------------------------------------
为了验证线路的真实连通策略,我们提取了三网的详细跳数日志进行拆解分析。
中国电信路由分析
电信用户访问 HKHK_8 是纯正的 “亲儿子” 待遇。
去程和回程双向均经过 CTGNet(AS4809)CN2 骨干网。以北京电信为例,数据包从香港发出后,直接接入 CN2 骨干,再下发至各省市本地网络。
这种路由策略最大程度避开了拥堵的 163 传统骨干网。
----------------------------------------------------------------------
正在测试: 北京电信 [219.141.147.210]
...
4 69.194.165.81 * 中国 香港 电信/CTGNet
5 69.194.166.117 * 中国 香港 电信/CTGNet
6 203.22.178.98 * [CTG-CN] 中国 香港 CN2-CTG CTGNet
7 *
8 59.43.132.17 * [CN2-BackBone] 中国 北京 chinatelecom.cn 电信
9 *
10 *
11 106.120.254.6 AS4847 [CHINANET-GD] 中国 北京 bj.189.cn
12 219.141.147.210 AS4847 [CHINATELECOM-BJ] 中国 北京 bj.189.cn
>>> [智能分析] 线路判定 (目标: CT):
类型:电信 CN2 GIA (AS4809)
详情:检测到回程国内段走 AS4809,顶级线路。
----------------------------------------------------------------------
中国联通路由分析
很多建站用户担心联通访客的体验,HKHK_8 在这里的处理方式非常硬核。
它并没有将流量直接抛给联通的国际出口,而是花高成本让流量先走电信的 CN2(AS4809)骨干网过境,进入中国大陆境内后,再移交给联通的 CU 169 骨干网。
以上海联通的日志为例,可以清晰看到 59.43 开头的 CN2 节点。
----------------------------------------------------------------------
正在测试: 上海联通 [210.22.97.1]
...
4 69.194.169.205 * 中国 香港 电信/CTGNet
5 69.194.166.250 * 新加坡 电信
6 *
7 59.43.185.169 * [CN2-BackBone] 中国 上海 X-I chinatelecom.cn 电信
8 *
9 219.158.38.241 AS4837 [CU169-BACKBONE] 中国 上海 chinaunicom.cn 联通
10 *
11 *
12 112.64.250.202 AS17621 [APNIC-AP] 中国 上海 chinaunicom.cn 联通
13 210.22.97.1 AS17621 [CNCNET-SH] 中国 上海 闵行区 chinaunicom.cn 联通
>>> [智能分析] 线路判定 (目标: CU):
类型:电信 CN2 GIA (AS4809)
详情:检测到回程国内段走 AS4809,顶级线路。
----------------------------------------------------------------------
中国移动路由分析
移动的网络环境通常是三网中最差的,但在 HKHK_8 面前同样被强行优化。
其回程策略与联通类似:数据包先经由 CTGNet 接入电信 CN2 骨干网,抵达大陆境内后,转入 CHINANET,最终交由 CMNET(移动骨干网)完成末端分发。
以广州移动为例,即使是移动用户,也能享受到电信顶级线路的过境加持。
----------------------------------------------------------------------
正在测试: 广州移动 [120.196.165.24]
...
4 69.194.169.25 * 中国 香港 电信/CTGNet
5 69.194.169.94 * 中国 香港 美因河畔法兰克福 电信/CTGNet
6 *
7 59.43.250.49 * [CN2-Global] 中国 广东 广州 chinatelecom.cn 电信
8 59.43.130.125 * [CN2-BackBone] 中国 广东 广州 chinatelecom.cn 电信
9 *
10 *
11 *
12 *
13 *
14 221.183.71.82 AS9808 [CMNET] 中国 广东 广州 chinamobileltd.com 移动
15 *
16 120.196.165.24 AS56040 [APNIC-AP] 中国 广东 深圳 gd.10086.cn 移动
>>> [智能分析] 线路判定 (目标: CM):
类型:电信 CN2 GIA (AS4809)
详情:检测到回程国内段走 AS4809,顶级线路。
----------------------------------------------------------------------
底层真实的路由跳数,印证了前文晚高峰 0 丢包的测试结果。
这正是搬瓦工香港 HKHK_8 敢卖高价的核心技术壁垒。它通过购买昂贵的电信 CN2 宽带资源,彻底抹平了国内不同运营商之间的网络差异。
机房硬件与 IO 性能
很多高端线路的 VPS 为了控制带宽成本,往往会在宿主机硬件上偷偷缩水。但目前搬瓦工的 HKHK_8 节点已经全面升级了底层的硬件架构。全系换装了 AMD EPYC 处理器配合 NVMe 固态硬盘的方案。
对于建站业务来说,CPU 和磁盘 I/O 则决定了后端程序处理并发请求的绝对上限。我们先看 CPU 算力表现,这台机器分配了 2 核的 AMD EPYC-Genoa,主频接近 2.8GHz。
# Sysbench 多核并发压测 (60秒, 双线程)
[root@xxxx ~]# sysbench cpu --time=60 --threads=$(nproc) run
CPU speed:
events per second: 6499.50
General statistics:
total time: 60.0004s
total number of events: 389978
Latency (ms):
avg: 0.31
单秒处理约 6500 个 event,平均计算延迟仅为 0.31ms。这种核心算力应对常规的 Web 运行环境绰绰有余。即便运行整套前后端应用、缓存中间件全量容器化部署,系统负载也能保持在极低的健康水位。
接下来是决定数据库性能命脉的磁盘 I/O 测试。测试机的存储分配为 39.2 GB,我们直接使用 fio 工具跑进行的 4K 随机读写的测试。
# 4K 随机写测试 (60秒)
[root@xxxx ~]# fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --size=1G --runtime=60 --time_based
...
randwrite: (groupid=0, jobs=1): err= 0: pid=22375: Wed May 27 10:02:03 2026
write: IOPS=87.3k, BW=341MiB/s (358MB/s)(20.0GiB/60022msec); 0 zone resets
...
Run status group 0 (all jobs):
WRITE: bw=341MiB/s (358MB/s), 341MiB/s-341MiB/s (358MB/s-358MB/s), io=20.0GiB (21.5GB), run=60022-60022msec
# 4K 随机读测试 (60秒)
[root@xxxx ~]# fio --name=randread --ioengine=libaio --iodepth=1 --rw=randread --bs=4k --size=1G --runtime=60 --time_based
...
randread: (groupid=0, jobs=1): err= 0: pid=22379: Wed May 27 10:03:19 2026
read: IOPS=6016, BW=23.5MiB/s (24.6MB/s)(1410MiB/60001msec)
...
Run status group 0 (all jobs):
READ: bw=23.5MiB/s (24.6MB/s), 23.5MiB/s-23.5MiB/s (24.6MB/s-24.6MB/s), io=1410MiB (1479MB), run=60001-60001msec
企业级 NVMe 固态硬盘的底层优势在这里体现得非常直观。4K 随机写入达到了惊人的 8.7 万 IOPS,写入带宽稳定在 341 MiB/s。随机读取也保持在 6000 以上的 IOPS。
对于后端架构来说,这个数据意味着极其出色的数据库落地性能。
如果你的业务涉及复杂的 PostgreSQL 高频写入与 ORM 映射,或是需要维护 MySQL 的主从 GTID 强一致性同步。这种级别的底层 I/O 能确保高并发下的事务提交,绝对不会卡在磁盘等待的瓶颈上。
搬瓦工香港 CN2 GIA 在售套餐与库存
看完底层网络和硬件数据,我们来看落实到具体业务的成本。
目前搬瓦工香港 HKHK_8 机房的在售套餐矩阵非常清晰。入门款从 89.99 美元/月起步,这个价格确实高昂,直接物理屏蔽了绝大部分折腾低价节点的 “邻居”。而且全系标配 1 Gbps 的超大端口。
在寸土寸金的香港 CN2 GIA 骨干网上提供 G 口带宽,这就是它敢定这个价格的底气。以下是目前该机房的完整套餐规格与价格参考:
| CPU 配置 | 内存 (RAM) | 硬盘 (RAID-10 SSD) | 月流量 | 带宽端口 | 月付价格 | 购买直达 |
|---|---|---|---|---|---|---|
| 2 Core | 2 GB | 40 GB | 500 GB | 1 Gbps | $89.99 | 立即购买 |
| 4 Core | 4 GB | 80 GB | 1 TB | 1 Gbps | $155.99 | 立即购买 |
| 6 Core | 8 GB | 160 GB | 2 TB | 1 Gbps | $299.99 | 立即购买 |
| 8 Core | 16 GB | 320 GB | 4 TB | 1 Gbps | $589.99 | 立即购买 |
| 10 Core | 32 GB | 640 GB | 6 TB | 1 Gbps | $989.99 | 立即购买 |
| 12 Core | 64 GB | 1 TB | 8 TB | 1 Gbps | $1,889.99 | 立即购买 |
搬瓦工虽然贵,但是物有所值。
如果你运营的是对可用性要求极高的商业项目,这笔服务器开销是不应该省的。例如涉及大量图片资源高频并发加载的图库、带有严格鉴权逻辑的会员核心系统,或者直接产生现金流的外贸交易站点。
在这些场景下,网页晚加载 1 秒,或者晚高峰出现哪怕 1% 的丢包,导致的用户流失和订单跳损,其代价远超每个月这几十甚至几百美元的服务器月租。让后端架构稳如磐石,这才是高阶服务器的价值。
选购建议与业务场景评估
对于这台机器的选购逻辑,结论非常单一:你的业务产生的现金流,能否覆盖它高昂的服务器成本。
如果你只是想搭建一个个人博客,或者项目还处于早期的方向验证阶段,不要在这台机器上浪费任何预算。但如果你的商业模型已经彻底跑通,且核心用户在中国大陆,那么 HKHK_8 就是最优解。
特别是在一些对网络质量极度敏感的变现场景中。比如客单价极高的跨境电商独立站,晚高峰时网页多加载 1 秒,流失的单笔订单利润往往远超这几十美元的服务器月租。
用预算换取网络质量的绝对稳定,将精力完全释放到业务和内容本身,是成熟架构中最理性的投资。
由于上游电信 CN2 GIA 骨干网的带宽极其昂贵且总容量有限,如果你在评估后确认业务线必须依赖这种顶配网络,且目前官网刚好释放了资源,建议直接锁定并前往控制台完成部署。
前往搬瓦工官网查看当前 HKHK_8 实时库存状态